I am fortunate to have the opportunity to continue working from home during the pandemic. As myself and my family adapt to a new normal in a new working space at home, a way of notifying them when I’m on a call would prove useful.
So if you own a Plantronics (now Poly) headset, and have a Philips Hue Bridge with a light, I’ll explain how to build a little one-line script and have it light up when on a call. I love Plantronics (umm… Poly) stuff!!!
This works pretty much independent of the software you use to make calls or join meetings, because we’re pulling call state from the headset, not the apps. Teams, Zoom, WebEx, Jabber, Skype for Business, the script does not care. If the Hub Desktop supports it as communications platform (and they support quite a few) then it’ll work.

Here’s the summary of steps:
- Install the Hub Desktop software. This exposes a local API endpoint that you can query for when your headset is active.
- Create an authorized user on your Hue Bridge so you can send it commands via REST API.
- Find the Light ID of the bulb you’re trying to change state
- Set up a Scheduled Task to run PowerShell, query the Hub Desktop API and send commands to the Hue Bridge when call state changes.
Step 1: Pretty straightforward: go here and run the software. This will expose an API endpoint locally on port 32017 meant for third party app integrations. You can only access this via localhost/127.0.0.1, it does not listen on other interfaces. The endpoint we are interested in is http://localhost:32017/Spokes/CallServices/CallManagerState
Step 2: Navigate to https://IPOFYOURHUB/debug/clip.html then use URL of /api, Body of {“devicetype”:”PolyHue#LAPTOP”} (change the json value to whatever you want, but the example will work), then go to your Hue Bridge, press the big button and press POST. You’ll get a username value back in the json response. COPY IT somewhere, as this is your key to sending authenticated API commands to the Hue Bridge.
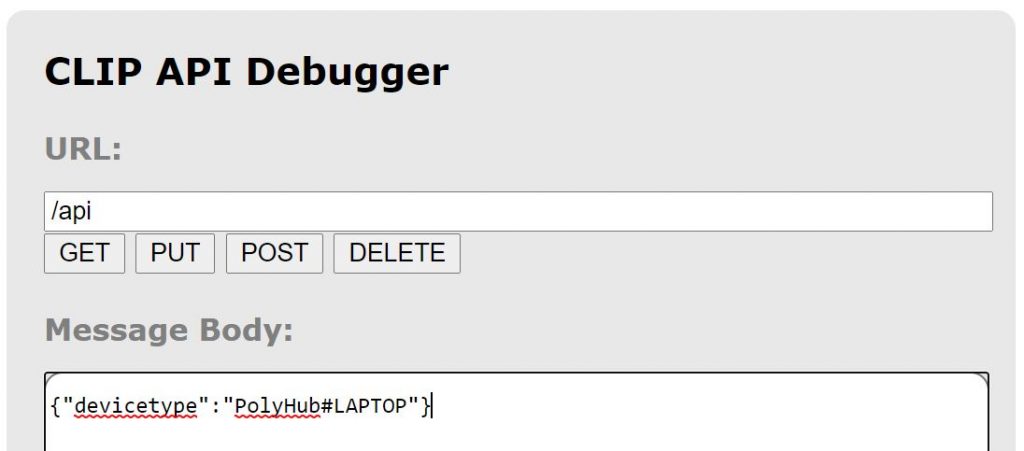
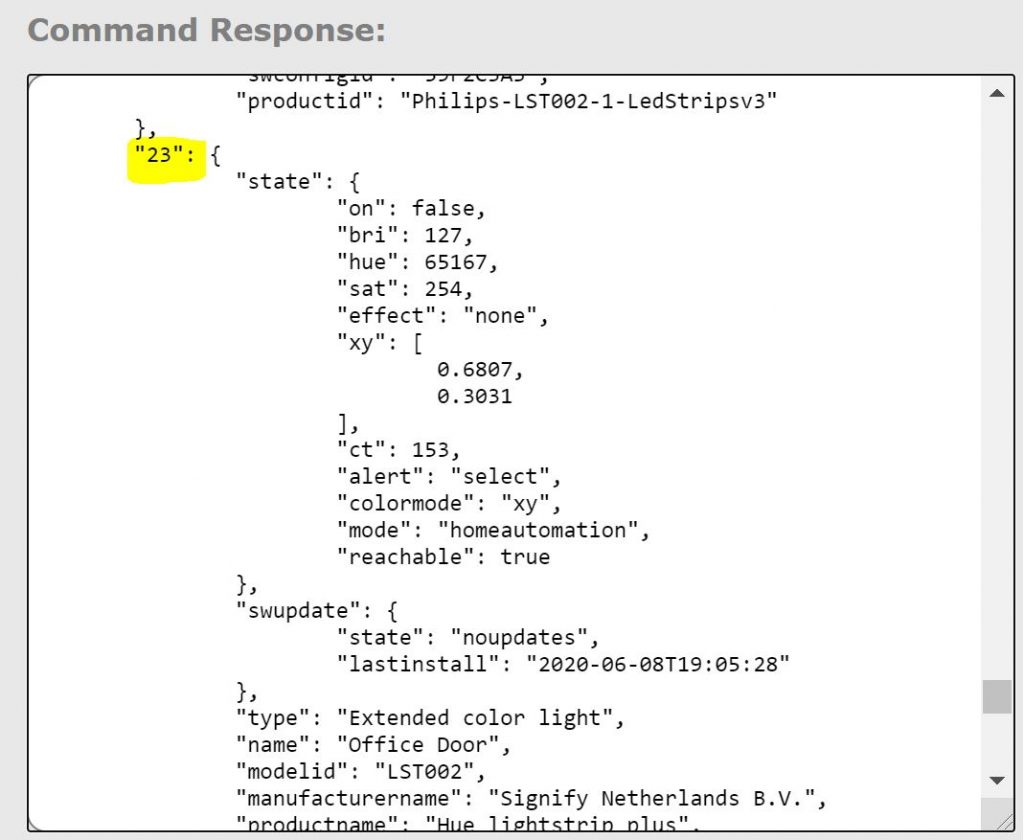
Step 3: Before you close the API Debug tool from your Hue Bridge, change the URL to /api/USERNAME/lights, using your new API username from Step 2, then press GET. Look at the json response and find the root number that matches the name of the light you’re using. They will be simple numbers, and in my case it’s “23”
Step 4: Set up a Scheduled Task to run At log on, and also set it to restart every 5 minutes for 999 times in case it quits because of a network disruption. Then have it run “powershell” with the following arguments pasted in and edited for your settings. Replace BRIDGEID, USERNAME and LIGHTID with your values.
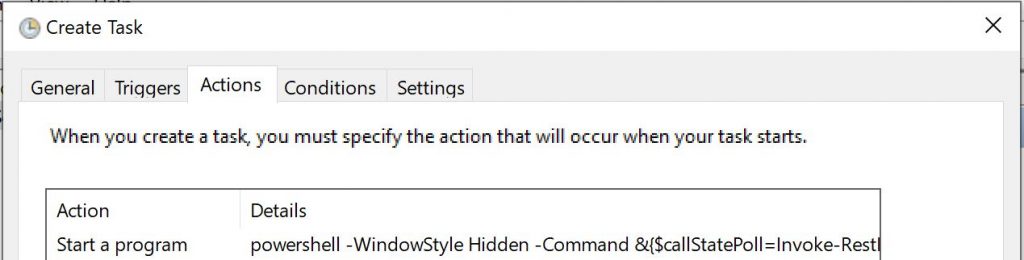
-WindowStyle Hidden -Command &{$callStatePoll=Invoke-RestMethod -Method GET -Uri http://localhost:32017/Spokes/CallServices/CallManagerState;while($true){$oldCallState = $callStatePoll.Result.HasActiveCall;$callStatePoll = Invoke-RestMethod -Method GET -Uri http://localhost:32017/Spokes/CallServices/CallManagerState;$newCallState = $callStatePoll.Result.HasActiveCall;If ($oldCallState -ne $newCallState){Switch ($newCallState){$false {$body = @{"on"=$false} | ConvertTo-Json;Invoke-RestMethod -Method PUT -Uri http://BRIDGEIP/api/USERNAME/lights/LIGHTID/state -Body $body};$true {$body = @{"on"=$true} | ConvertTo-Json;Invoke-RestMethod -Method PUT -Uri http://BRIDGEIP/api/USERNAME/lights/LIGHTID/state -Body $body}}};Start-Sleep -Seconds 5}}Now to test it, turn on the light, set it to the desired brightness and color, then turn it off. The script will check every 5 seconds your call state, and if it changes, it will flip the light on if you have an active call, and off if you don’t.
The main gotcha: This will only work when using a Plantronics/Poly headset, as we rely on the API from Hub Desktop to give us call state. Jabra Direct software may work but couldn’t get the right API endpoints to query call state.
Hope it helps someone out there, and stay safe!